作为大模型的最主要应用场景之一,RAG技术需要配合大模型和向量模型来落地,而诺谛“支点”向量模型目前在中文C-MTEB排行榜中排名第一,这也是诺谛智能在制造业场景化实践中深厚的数据积累以及训练算法持续创新的体现。
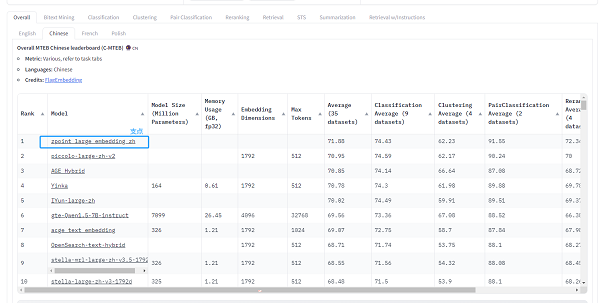
C-MTEB被公认为是目前业界最全面、最权威的中文语义向量评测基准之一,涵盖了分类、聚类、检索、排序、文本相似度、STS等6个经典任务,共计35个数据集,为深度测试中文语义向量的全面性和可靠性提供了可靠的实验平台。
此次获得C-MTEB榜单排名第一的诺谛“支点”向量模型,采用了多样化困难样本采样策略,其针对分类和聚类、检索、排序以及句对匹配任务设计了不同的困难样本选择策略。同时该模型还采用了基于诺谛“支点”行业大模型的数据合成,通过多样化的数据合成策略对分类、聚类、句对匹配样本进行重写,为每个样本构造出多个合成样本,并针对检索和排序任务对问题和文章同时进行增强,可生成多个检索问题。此外,对于不同场景的检索任务,“支点”向量模型还设计了多样化损失函数,结合梯度累积策略以及数据调度策略,最终使诺谛“支点”向量模型在分类、聚类、句对匹配、检索、排序任务上的性能大幅提升。
在实际应用中,“支点”向量模型为了满足不同业务实际场景对向量的差异化需求,在训练过程中引入了MRL技术,可根据指定维度的向量计算多个附加损失,使其可以输出不同维度的向量用于下游任务,进一步提升实际业务场景下分类、聚类、检索、排序、文本相似度等任务的AI能力。
未来,随着“支点”向量模型的持续创新和迭代,将进一步减少数据的复杂性和计算资源的需求,在推动AI行业技术持续创新的同时,助力诺谛为更多制造企业交付高效高质量的场景化AI解决方案,实现智能化升级。